Why 1 Token Is Not Exactly 1 Word In Language Model?
When I was exploring API pricing of Large Language Model (LLM) provider, I was baffled by the term “token”. It says “$X per 1M token”, what does it mean? Is it 1M words? 1M characters?
So I tried looking at a site and found what is called Tokenizer. An interactive tool to show how token is calculated. I used this sentence as input
You are impossibly real
and guess what? Are there 4 words or 23 characters?
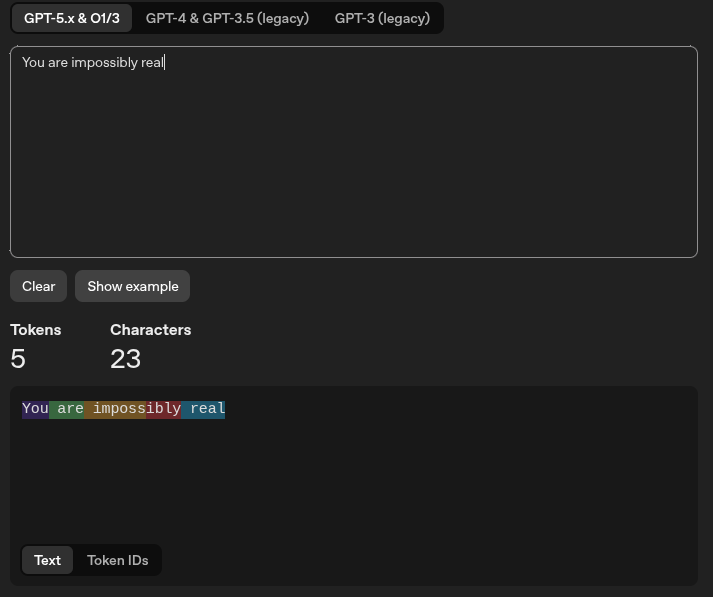
Hm. Neither. Seems “impossibly” is a word but not a token. It is not exactly one word but could be one word. In short, “it depends”. How come? How exactly can we know how much token in a sentence or even a word?
To find out about this, I spent time to learn how tokenizer works.
Summary
In short, a tokenizer requires a “vocabulary”. This vocabulary is a list of known words and characters by tokenizer. If you ever buy an English dictionary or even search a word on online dictionary, there is a chance that some particular word does not exist in the dictionary although it is grammatically correct. That is also the case for vocabulary in tokenizer. So what happens if the word does not exist? This tokenizer instead break down the word into characters to find what is the “known token”.
Take previous example for the word “impossibly”. In the previous picture, we can see the word is partially highlighted until “imposs”. After that, “ibly” is highlighted with different color. This means the tokenizer see the word “impossibly” as
imposs + ibly = impossibly
where “imposs” is 1 token and “ibly” is 1 token.
This separation happens because its vocabulary does not have word “impossibly” but it has word for “impossible”. So it can only tell “imposs” is 1 token. Why just “imposs” ? Let’s define token as a series of character first. Which sounds like “word” but unlikely true as we know it.
The tokenizer vocabulary is unlike a common English dictionary. It may look like this:
- im
- imp
- impo
- impos
- imposs
- impossible
- possibly
- ibly
Weird, huh? Well, that is also interesting since when it is looking into the word “impossibly”, it breaks down into “i-m-p-o-s-s-i-b-l-y” first. After that, it starts to pair each character then look back into vocabulary for reference. Say, we pair “i-m” to be “im” then check the vocabulary, if it exists, continue to pair “imp” then check again, keep going until it is unable to find the token in vocabulary. Hence it stops at “imposs” then consider it as 1 token since “imposs” exists in the vocabulary. So that is how tokenizer works and why 1 token is not always 1 word. It depends.
Note: I’m not an AI researcher, scientist or an expert in this field. This blog is pure exploration and notes on what is my current understanding about components of AI. Please do clarify with someone who knows better.
The Long Journey Of Stressful Discovery
As I try to understand what tokenizer is, I had a “private course” with AI to teach me about it and still, despite I get the idea of vocabulary, chunking, encoding, something just doesn’t click. I already get the basic principle, it’s just breaking down words into characters then rebuild it into a series of character. Yet I’m still itching to know the intricate details. It is like being told a food tastes bad but you still want to try it.
Rebuilding For The Sake Of Knowing
I decided to rebuild a tokenizer. Not a better tokenizer, nor rewrite existing tokenizer that was widely used. Just to know how tokenizer is working and what is the tradeoff that was made. For this, I setup an AI as my private tutor to patiently guide and review my implementation whether it is right.
Remember about the first picture I’ve shown about tokenizer that counts a sentence “You are impossibly real” has 5 tokens although it has 4 words? There are several questions that I was trying to answer:
- Why the other words are fully highlighted in one color but the word “impossibly” has 2 highlight colors? “imposs” and “ibly” have different color although there is no space between it and it is a single word based on English dictionary.
- Was the tokenizer “reading” by character or by syllable?
- Was the word “impossibly” not recognised as an English word by the tokenizer?
- What “imposs” and “ibly” mean for the tokenizer?
Talking About Data
When faced with these questions, my intuition tells me it all leads into one thing. Data. The most underrated and boring thing to work on yet AI need it the most. I’ve often heard about the importance of data when building an AI, so I try to make the tiniest dataset for the sake of experiment.
you are real
you are impossible
it is impossible
that is not impossible
she is really fast
you are really happy
this is reliably good
that player is terribly bad
he is reliably good at his job
it was forcibly removed
That was generated by AI and I added more and replaced some words in hope the end result would mimic the tokenizer that we’ve seen before. The tokenizer uses this dataset to “learn” and build its “vocabulary”.
Tokenizer Methods
As I mentioned in the summary, there are several methods that is used by tokenizer. What I’m trying to rebuild here is the one that is called BPE (Byte-Pair Encoding). Though not a perfect one since I focus on basic principle. How to think about BPE is, instead of remembering words one by one, it remembers compound character sequences that frequently occur together. What does that mean? Let’s say when you first time learning english, you would memorise each word in the dictionary. As you grow your english vocabulary you remember words like
- unpredictable = not predictable
- unusual = not usual
- unsure = not sure
- believable = can be trusted
After that you hear a song with lyric that has word “unbelievable”, how would you guess the meaning of it? There are two ways:
- Look into dictionary.
- Guess the meaning by breaking the word into “un-believable” then recall similar word that starts with “un” and connect it with word “believable”
BPE is like the second approach. It doesn’t remember all words but it breaks down into subwords and characters. When it frequently learns many word starts with “un” then it will put it in its own “vocabulary”. So later, when it encounters a new word that hasn’t been learned before, it will break it down into subword then try to find similar word.
Training
Let’s start building tokenizer now. One thing that I never realised, “model” does not apply on LLM only. Even tokenizer needs a “model”. Borrowing definition from TDWI, a model is “a very sophisticated pattern-recognition system”. There it is, tokenizer does pattern-recoginition from a word hence it requires a training to build a model.
I’ve written a small program that does the training and encoding. This could be helpful if you prefer to read the source.
https://codeberg.org/ky64/basic-language-model/src/branch/main/demo/tokenizer/tokenizer.ml
In this blog I will explain the high-level concept of the steps.
Step 1. Transforming Data
We have the ingredients now (dataset). Let’s start cooking. First, we need to chop it into the tiny piece so it can easily blend the flavor. Yes, I mean it. We need to break it down into characters here. Why? We are teaching the tokenizer to spell a word first. Like “real” is “r-e-a-l”. So what we have to do is breaking down this dataset into words, then into characters.
1. Break Down Into Words
Let’s break down this sentence into words:
that is not impossible
becomes
["that"; "is"; "not"; "impossible"]
2. Break Down Into Characters
After that we break the words into characters
[
["t"; "h"; "a"; "t"];
["i"; "s"];
["n"; "o"; "t"];
["i"; "m"; "p"; "o"; "s"; "s"; "i"; "b"; "l"; "e"]
]
We do this for all the sentences in dataset and now we have a bunch of characters ready to be used by the tokenizer
Step 2. Creating Initial Vocabulary
After breaking down into characters, all of these characters will end up in the vocabulary. Yes, the vocabulary is unlike a common English dictionary. It contains character, later it will contain subwords, and words. We could stop here and simply just generate the all possible unicode characters in the vocabulary. Yet this will not answer the question why “imposs” and “ibly” are considered different by tokenizer. If the vocabulary contains just characters, each character counted as 1 token. However, by storing characters, we already help the tokenizer to recognise unknown words. Since when it break it down into character, it can find the matching character in the vocabulary.
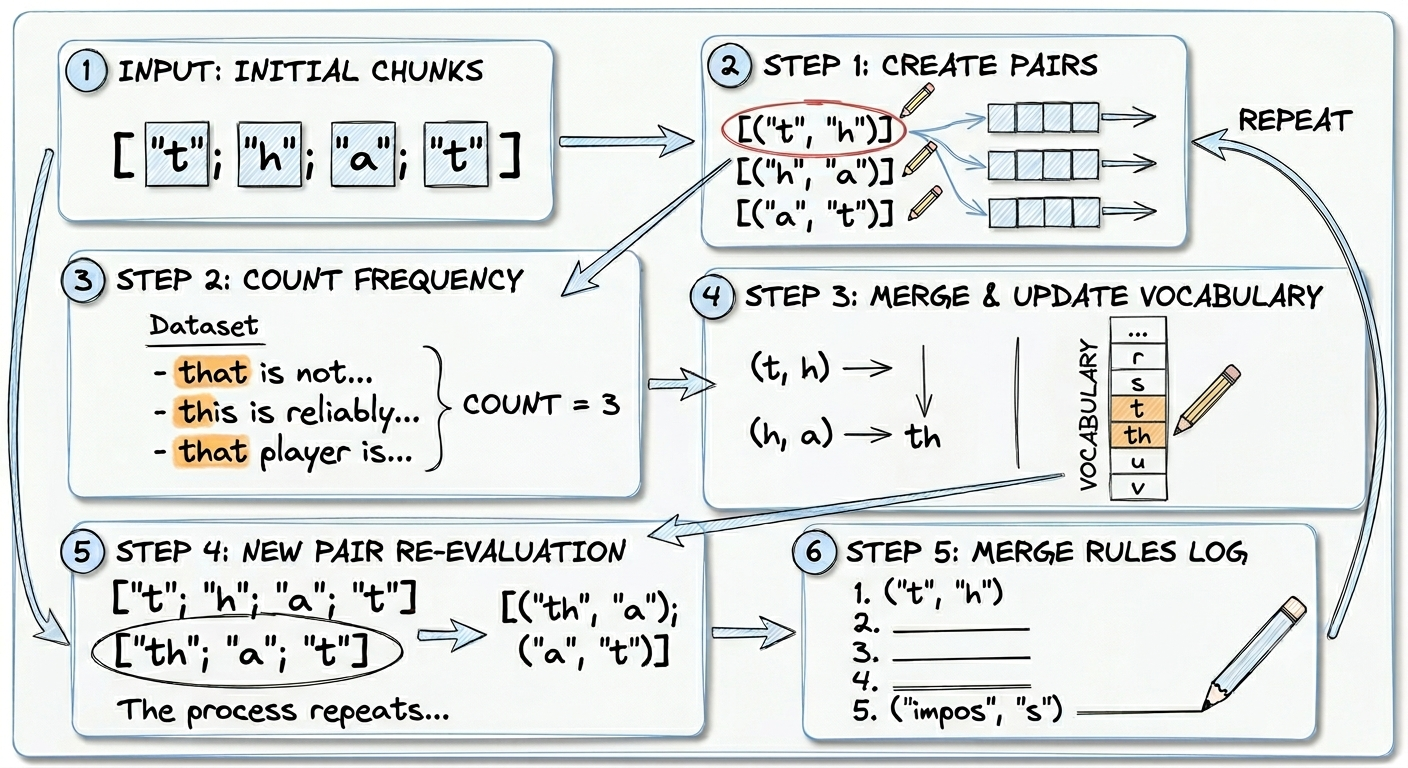
Step 3. Pairing Characters
This is the step that shows how BPE tokenizer able to recognise partial word but not entirely. It creates a pair of character and check if it is frequently appear before merging the pair into a new token.
1. Creating Pair
Suppose we have the following character:
["t"; "h"; "a"; "t"];
we will create a pair of this word into
[("t", "h"); ("h", "a"); ("a", "t")]
2. Counting Frequency
Once the pair is created, it will go through all existing pairs to check how often the pair occurs. Starting
from the first pair [("t", "h")].
In the dataset, we have 3 sentences that contains this pair
- that is not impossible
- this is reliably good
- that player is terribly bad
From here we know that this pair has appeared 3 times.
3. Merging Top Most Frequent
After counting how often each pair occurs, it will find the top most frequent. Let’s just simplify this, assuming we get the following result
("t", "h")appears 3 times("h", "a")appears 3 times
in this case we need to pick the most frequent, what happen if they both have the same frequency? Order matters.
It will pick what got counted first. Since we started counting from ("t", "h") then it will be the one that gets
merged. After merging it to become "th", this merged pair is included in vocabulary. Previously our vocabulary
looks like this (trimmed for simplicity)
---
r
s
t
u
v
---
after merging the first pair, it is included in the vocabulary and now we get
---
r
s
t
th <<< added a new token
u
v
---
4. New Pair
Once the pair is merged, the characters ["t"; "h"; "a"; "t"] is evolved into ["th"; "a"; "t"]. This happens
because “th” frequently match with characters in the dataset. So every pair which frequently appears will be
merged until it ends up becoming a subword or even a word, it depends on the frequency in the dataset. The new
pair would eventually looks like this
("th", "a")
This will go through the same steps like before to check if “tha” frequently appear in datasets.
5. Merge Rules
There is one thing that is special to BPE, it is called “Merge Rules” which is a guidance for the tokenizer
to reconstruct a token. Everytime a pair is merged, it will be added into merge rules. Say if we just merged
("t", "h") then the merge rules will have
("t", "h")
after training process is done. The merge rules could look like this (trimmed for simplicity)
("t", "h")
("i", "s")
("i", "m")
("im", "p")
("imp", "o")
("impo", "s")
("impos", "s")
the usage of this merge rules would be more obvious once we reach the encoding part to test the tokenizer. Here is the figure to summarise the previous steps.
6. Token ID
Every token in the vocabulary has an ID. Say when “th” is added into the vocabulary, it can have ID like 12 or anything. It is up to us how to set the ID. For simplicity, I just used the list index as ID. As long as the ID is unique for each token, it should work. So the vocabulary looks like this:
r = 9
s = 10
t = 11
th = 12
u = 13
v = 14
7. Expected Vocabulary Size
The training process also needs to know when to end. It can be done by checking the graph of the vocabulary size which if the size doesn’t grow after some iterations, it should end the training. However, for simplicity, we can set the parameter the size of the vocabulary, whether it is 30, 50, etc. It could be higher means more words but this is depends on the dataset. If the dataset has only limited words, the tokenizer is only as good as the dataset. Once the vocabulary size reached, the training ends and it means we have created a tokenizer model. In other words, the model is a list of learned tokens, hence called “vocabulary”.
Encoding
After training a tokenizer model, the next step is to test it by transforming a sentence into tokens. Which means, it needs to be able to transform
“You are impossibly real”
into
[you] [are] [imposs] [ibly] [real]
like the example tokenizer. For this case, the output will the token ID which map to the vocabulary.
The encoding step follows the same steps like the training. It breaks down sentence into word then into characters. However, it doesn’t create a new vocabulary but it looks into vocabulary for any known words. It is like testing your memory about english terms.
1. Transform Inputs
When it gets the input, it will transform the input into
[
["y"; "o"; "u"];
["a"; "r"; "e"];
["i"; "m"; "p"; "o"; "s"; "s"; "i"; "b"; "l"; "y"];
["r"; "e"; "a"; "l"]
]
If you wonder why not just matching the word to vocabulary, that was also my question. Apparently this is why BPE is interesting. Remember about dictionary analogy? When a word does not exist in the dictionary, how could it recognises the word then? So instead of using the word by word, it starts from character by character, then token by token.
2. Merge Rules
For refreshment, merge rules is a guide for how to reconstruct token. If it is faced with characters “y-o-u”,
the rules will guide to merge “y-o” first then “yo-u”. If it is still confusing why tokenizer has merge rules
and vocabulary. Let’s start to encode the first index, ["y"; "o"; "u"] as input.
Suppose the tokenizer vocabulary is
u = 13
o = 19
y = 20
yo = 22
you = 33
The ID is not deterministic, I assign it randomly just for example. So how the tokenizer knows which token ID to
use from the vocabulary? Will the input encoded to [20; 19; 13] or [33] or [22; 13] ?
All of them are correct but can we make the tokenizer to choose [33] instead? This is where merge rules can be
useful. So instead of directly check the vocabulary, it will first check the merge rules.
When checking the merge rules, the tokenizer will create pair of the characters first, just like it did during training. So it will try to create this pair first
[("y", "o")]
Then try to find in the merge rules how to merge this pair, if the pair exists in the merge rules, then it will merge it. For example the merge rules are
[("a", "r")]
[("y", "o")]
[("yo", "u")]
As we can see above, the merge rules tell the it should merge [("y", "o")] so it will merge it first into “yo”
after that it will create a new pair
[("yo", "u")]
Then check again in the merge rule, does it exist? Yes, so it will merge it into “you”. Now, after merging all
the pairs, it is now checking the vocabulary whether token “you” exist then assigning the token ID. Hence, the
word “you” is transformed into [33].
What about the case on “imposs” and “ibly” ? Remember that merge rules is not just a list of character pair. It is a list of most frequent pair. The reason the word “impossibly” is counted as 2 tokens here is due to three possible factors:
- In the dataset, the pair
[("impos", "s")]and[("ibl", "y")]are frequently appears hence it is added in the merge rules. While[("impossibl", "y")]and[("impossib", "l")]pairs are not frequent enough. - The dictionary size set to limited number, so it may requires more training.
- The word “impossibly” itself is not frequently appears in dataset.
3. Transform to Token ID
The final step on encoding is transforming based on its token ID in the vocabulary. So the end result would look like
[33; 4; 29; 24; 44]
Assuming the vocabulary is
you = 33
are = 4
imposs = 29
ibly = 24
real = 44
Final Answers
So that is how tokenizer works. Though it is not a perfect BPE but at least I get the idea of how tokenizer works. Let’s answer our initial questions:
- Why the other words are fully highlighted in one color but the word “impossibly” has 2 highlight colors?
Because during training the word “impossibly” is not frequently appears and the tokens “imposs” and “ibly” are more frequent
- Was the tokenizer “reading” by character or by syllable?
It breaks down into characters then merging it to build a token based on merge rules
- Was the word “impossibly” not recognised as an English word by the tokenizer?
It may exist in the dataset but not end up in the vocabulary since it is less frequent
- What “imposs” and “ibly” mean for the tokenizer?
It means the token “imposs” and “ibly” are frequently appears in the dataset so it is included in the vocabulary
It is a long journey. As I finish this article, a more sophisticated frontier model has released a while ago, Claude Fable 5. Yet whatever the model is, the step to build an AI model still the same. Hence I learn the basic principle and fundamental truth to understand how to build a custom model.